Kiko
| Você está aqui: Kiko > TrecosDoExcel > PlanilhaMascFemPtBr | Imprimível | fim do tópico |
Start of topic | Skip to actions
| English Version |
Masculino ou Feminino?
Digite um nome próprio brasileiro típico e a planilha lhe dirá se ele é masculino ou feminino. Nos meus testes, ele acerta mais de 99% das vezes.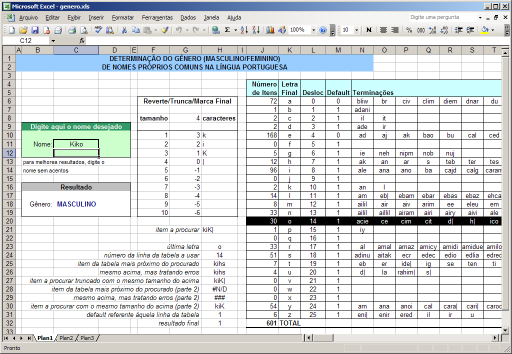
Clique na imagem para baixar a planilha
Sobre o algoritmo
Primeiro ele determina a última letra do nome. Para cada letra há um default e uma tabela de terminaçőes que săo exceçőes. As terminaçőes estăo com as letras invertidas em ordem alfabética para que a funçăoPROCH do Excel aja como um batimento parcial por prefixo. Em certas situaçőes é necessário um batimento exato; para isso servem as barras verticais no fim de algumas delas.
Se o nome constar na tabela de exceçőes, o resultado será o inverso do default; caso contrário, será o default. Zero é feminino, um é masculino.
Exemplos:
- "Kiko" termina com "o", e o default para a leta "o" é 1 (masculino). Tiramos o "o" final e invertemos: o resultado dá "kik". Essa string năo consta na tabela de exceçőes, nem nenhum prefixo dela, entăo o nome é masculino mesmo.
- "Babi" termina com "i", e o default para essa letra é 1 (masculino). Tirando a letra final e invertemos, temos "bab"; o prefixo "ba" consta na tabela de exceçőes da letra "i", entăo o nome é feminino. (Se vocę tentar esse nome na planilha, verá que o "ba" fica em vermelho, indicando um batimento).
PROCH pode lidar. Por isso, foi necessário partir a busca em dois. Curiosamente, só a letra "e" requer a segunda busca.
O Excel traz automaticamente alguns benefícios para nós; por exemplo, a comparaçăo usada na funçăo PROCH năo distingue maiúsculas de minúsculas, o que nos poupa o trabalho de converter. As configuraçőes regionais do Windows também ajudam: a comparaçăo descarta acentos, de sorte que "á" é considerado igual a "ŕ" que é considerado igual a "a". Isso nos poupa o trabalho de implementar um removedor de acentos.
O segredo do algoritmo, naturalmente, está na tabela. Em uma lista de nomes e sexos (principalmente resultados de corridas, tais como a Săo Silvestre e as promovidas pela Corpore) foi rodado um algortimo de particionamento recursivo por sufixo. Ele chegou ŕ tabela mínima de sufixos necessária para implementar uma árvore de decisăo que proveja o exato mesmo resultado da lista original. Contudo, o uso de sufixos mínimos adiciona a capacidade de lidar com nomes que năo constavam na lista original. Assim, chegamos a uma tabela relativamente compacta (601 elementos, como mostra o total geral na planilha) que contém os sufixos determinantes; isto é, aqueles que săo realmente os decisivos para determinar o gęnero da palavra.
Curiosidades
A tabela mostra que os nomes terminados com a letra "e" săo os mais difíceis de decidir: eles normalmente săo femininos, mas há 168 casos particulares que os tornam masculinos. Os outros mais difíceis săo os sufixos "i", "a", "y", "s", "n", "r", com 96, 72, 54, 51, 33 e 33 exceçőes, respectivamente. No outro extremo, a tabela aponta os sufixos "f", "j", "q", "v", "w" e "x" como sempre masculino, sem exceçőes. Isso é um reflexo do fato que o banco de dados no qual nos baseamos năo tinha nomes femininos terminados nessas letras, mas parece temerário afirmar que năo existam. O default de quase todos os sufixos é masculino; excetuam-se apenas os sufixos "e" e "a". Isso concorda com a percepçăo comum de que nomes próprios terminados com "a" quase sempre săo de mulher. Feministas fanáticas possivelmente notarăo esse fato como uma corroboraçăo de que a desproporcionalidade masculina na ocupaçăo de espaços se estende também aos nomes próprios.Valor Didático
Eu costumava usar esse problema em cursos de programaçăo como exemplo de finesse/teoria versus prática desabalada: pegue algum programador e peça para ele escrever na măo um programa para fazer isso. Depois rode-o contra um banco de dados. Dificilmente ele conseguirá uma precisăo muito maior que 95% -- e o código tipicamente fica uma nojeira e o desafiado sai exausto. Usando a abordagem correta, uma soluçăo bem melhor sai com muito menos esforço. Por outro lado, se o desafiado partisse logo de cara para buscar um banco de dados e tentar uma abordagem semelhante a essa, é sinal de que ele já tem mais tino.Implementaçőes em Outras Linguagens
- Em Perl: Lingua-PT-Gender-1.03.tar.gz
- Em Visual Basic for Applications em um
.MDBdo MS Access 2003: genero-v1.01.zip
Contribua!
Se vocę tem acesso a um cadastro de nomes próprios confiável e bem mantido, com mais de 500 mil nomes, que contenha o sexo do indivíduo (masculino/feminino) e que vocę năo se importe em e/ou năo teria restriçăo divulgar, por favor me mande! Preferivelmente em formato CSV com dois campos: nome completo e sexo. Com seus dados poderemos refinar as tabelas para obter mais precisăo, testar novas técnicas, etc. Năo deixarei de dar crédito a todos que participarem. Năo divulgarei o banco de dados, a menos que me seja dada permissăo explícita para isso. Bancos de dados de nomes próprios de outros países que năo o Brasil também săo aceitos. Tenho curiosidade de saber o quanto esse algoritmo simples seria eficiente em nomes de outros idiomas. Outra questăo em aberto é saber se seria possível gerar uma única tabela/algoritmo que desse precisăo aceitável para a maioria dos idiomas baseados no alfabeto latino.topo
